Today's links 18/11/2014: #microservices, #cloud , oracle CPU, automated deployment, #RDMA, Intel Omni-path
- Colossus : a lightweight framework for building high-performance applications in Scala that require non-blocking network I/O. In particular Colossus is focused on low-latency stateless microservices by tumlbr
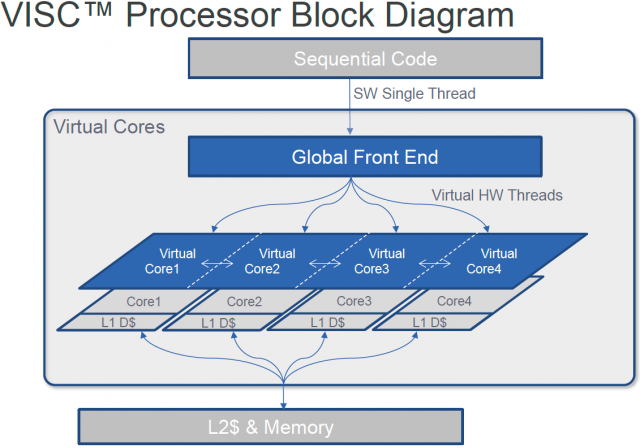
- M7: Next Generation Oracle Processor [ slides ]
- Appolo : shared internal deployment service at Amazon and its public pendant AWS code deploy
- RDMA in the cloud : Vmware demonstrate RDMA for virtual machine in cloud env but as usual with vmware presentation the graph scale are poorly chosen...
- Omnipath : Intel is gunning at infiniband with its new 100 Gbps fabric.