Amazon recently launched its own gaming engine :
Lumberyard. This should not seems as a surprise with the stream of high level investments they have been doing in the field over the past couple of years: Twitch.Tv or licensing Crytech engine (which form the basis of lumberyard) to name a few. Moreover, I will not extend on Amazon underlying strategic play as Simon Wardley already did brilliant job explaining it
here and
there.
A lot of discussions analyzing Amazon move have been centered around the long term strategic play in the AR/VR field. However, in the short term, Amazon might be aiming to accelerate the value chain shrinkage while potentially moving away from the traditional gaming industry business model to a service based approach and ultimately a complementary business model.
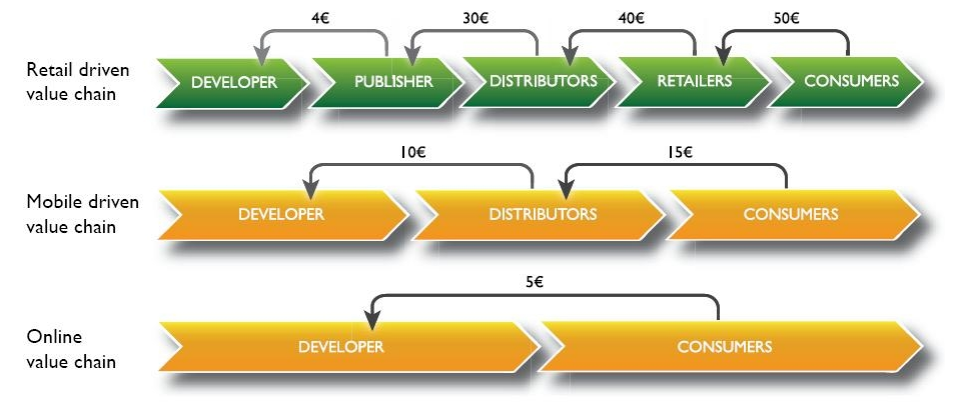
Historically, Work-for-hire & Royalty advance practices generated significant upfront fixed cost in the video game development business model which resulted in making publishers as the de facto main financial operator. Publisher typically mitigated these financial risks via portfolio management which exacerbate the reliance on franchise game (86% of the market).
With the switch to digital distribution platform and the explosion of mobile gaming, the physical logistics needs drastically decreased while the barrier to entry vanished. This commoditization trend effectively shrinked the value chain significantly as show in the diagram below.
Moreover technology evolution enabled an increased variety in revenue model :
- Subscription : Subscribers pay periodically to get access to the game (ex: World of Warcraft)
- Utility : metering usage, i.e. a pay as you go approach. This model is widely used among MMOs in China.
- Advertisement : sometime used in combination with other model in order to enhance revenue. Pure advertisement model are mainly found in mobile.
- Micro-transaction model : dominate Eastern markets
- Licensed : historical revenue model
- Free to play : combination of other revenue models , ex Advertisement + micro transaction.
There is two other business model that are still nascent in the gaming industry: Service and Complementary. And this is where, I believe, Amazon is aiming all along with its gaming push.
If we look at the value chain above Amazon's plan seems extremely straightforward. By facilitating production systems via “free” access to lumberyard Amazon facilitate the emergence of gaming studio. This open platform with efficient underlying support system (AWS) and with great customer exposure (Twitch.tv) will drive the commoditization of content creator and by transitivity content itself. This approach literally cut the grass under the foot of traditional gaming corporation that relied on a high barrier to entry ( via game engine licensing, distribution network, backend, etc..).
By analyzing beyond the pure technological aspect we can quickly theorize that Amazon might be aiming at pivoting the gaming revenue model completely. Amazon could push for a
Netflix like service model. However, there is a greater chance that it will follow the same approach it used for
Amazon Video. Amazon could start offering Video Game access (downloading via app store steam style first, streaming later) free as a complementary to Amazon Prime customers. Prime serving as an incentive and creating opportunities for more lucrative cross-sell and up-sell opportunities. The Gaming service attracts customers to Amazon store, where they can purchase the content which is not available for free, as well as other products from Amazon. Moreover the overall business model effect would be further reinforced through the Twitched.tv broadcast platform.
Obviously, to support and accelerate this model, Amazon will need to start producing its own games. It needs to offer an attractive gaming experience that cannot be easily replicated while co-opting the rest of the industry at the same time.
One of the key element regarding the pace of change will be dependent of the commoditization of the hardware platform and co-optation of existing one. If Amazon is able to broker a deal with MSFT or Sony ( the later is more likely because they already run their services on AWS). They would be able to gain a foothold in the gamer market. However, by co-opting the “hardcore” PC market , TV causal (Fire TV) and mobile, Amazon should be able to squeeze out the competition. Even if the console put up a fight, they would be able to enshrine in concrete any market gain by enrolling top game studio and capturing gaming franchise.
Last but not least, the value of console hardware is dropping fast while console software value is increasing and already exceeding hardware. Similar relations are to be found for handheld devices with an even greater gap. Amazon, just has to wait for for the gap to reach a critical point and then wipe out the nascent video game streaming industry by leveraging its existing expertise from VDI (
workspace). All of this would be a textbook replay of the Amazon Video strategy.
The future of gaming is about to enter a new era. While the AR/VR future is exciting there is a gaming business model war looming that will hit way before these technologies reach maturity.