“Launched ahead of their time” - a claim a lot of startups (and indeed more established companies) use to explain their product failure. In some rare cases, a product is truly ahead of it’s time, however, there is no market for it at all and no supporting component within the supply chain enabling it to be viable commercially and economically. But in most cases, these claims can be boiled down to a lack of traction from their offering.
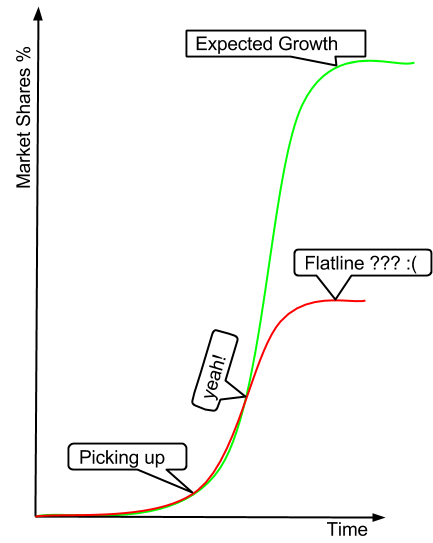
In this blog post, I will focus on the “prematurely interrupted” hockey stick growth curve that some companies experience and the misunderstanding surrounding same. It looks and feels like exponential growth, but the ride terminates far earlier than the potential market research predicted. Incomprehension, surprise and denial are often common when the sales flat-line occur because customer feedback was great. As a consequence, companies use the “ahead of their time” excuse to explain their failure. However, the truth is the market for the product they built simply dried up.
Often these companies misunderstood the true reality of the
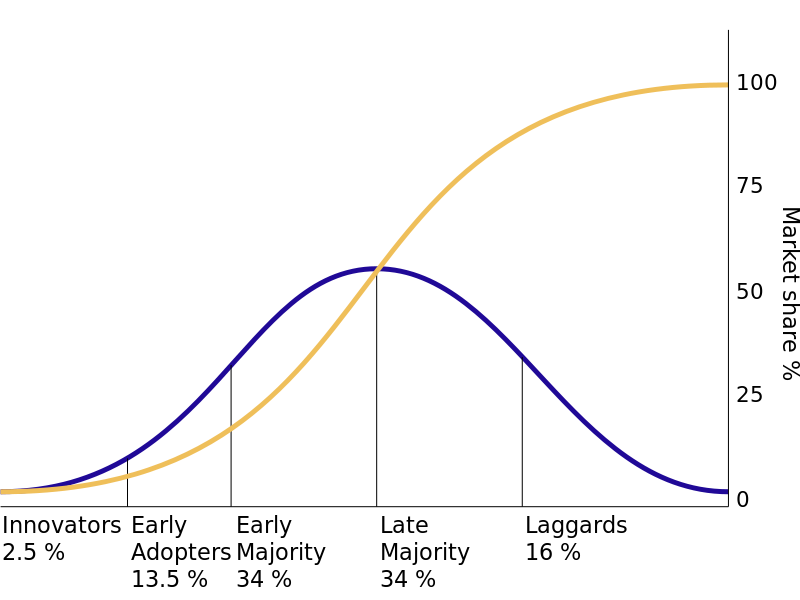
diffusion of innovations curve presented below. With successive groups of consumers adopting the new technology (shown in blue), its market share (yellow) will eventually reach saturation level. The interpretation is that the technology adoption implies same product consumption across a consumer group.
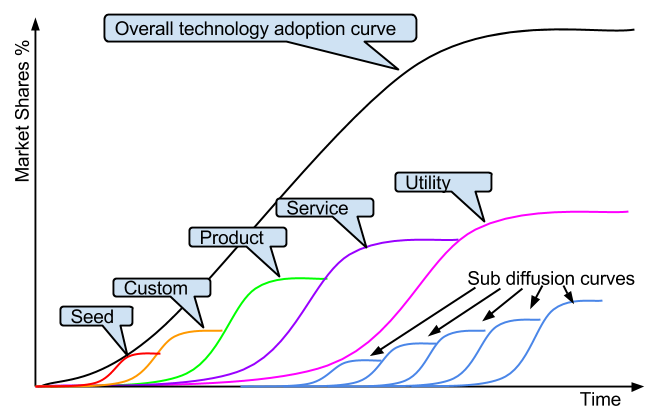
In this graph, each phase of the adoption is represented by a different customer group that requires a tailored product in order for them to adopt it. While the concept and technology to a certain extent is similar across each consumer group, the actual product may vary drastically in shape and form. As a result, the technology, product, and consumption model evolves with each phase at different pace. In the graphic below, I have overlayed the actual diffusion curve of each sub group on top of the diffusion of innovation curve, in order to make it clearer. Note that this concept is derived from
Wardley’s mapping technique tying diffusion and evolution within a single map.
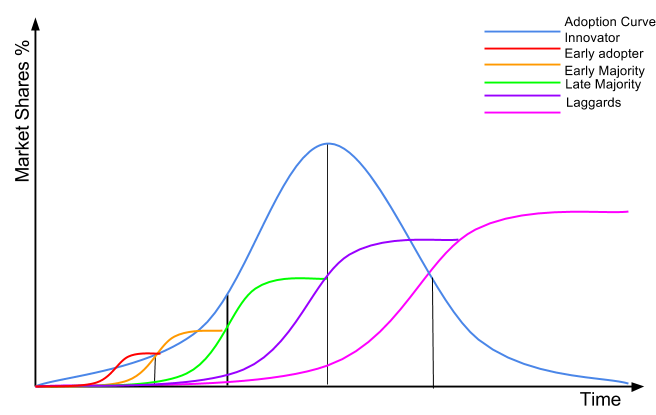
As you can see, each customer type represents an independent sub-market with its own characteristic and inertia. It can be extremely easy to become trapped within a sub customer ecosystem. Often companies validated their products within such subspace and show impressive stats along a number of dimensions, such as high engagement, viral coefficient, or long-term retention. However, what is important to understand is how big is the customer market you validate your product in as well as asking the question, does it belong to a bigger ecosystem? Without this information, a company can quickly end up trapped into a local maxima. As a result, companies get boxed into a line of creative design thinking making tiny incremental improvements but never looking beyond that one solution. They became addicted to positive reinforcement, created out of their customer feedback, thereby preventing them from looking beyond that one solution to an innovative solution along different creative lines of thinking. That's how a company ends up having
hipchat vs
slack. The only difference between the two is the packaging of technology and it allows one to thrive along a bigger diffusion curve, while the other one seems stuck.
As mentioned, the technology evolves over time and with each diffusion wave. Quite often from genesys, custom built, product, and finally utility. However,
there are many chasms to cross as there are a multitude of competing versions created, evolved (and dying). To be able to cross from one stage to another requires not only to understand the technological requirements of the new consumption model for the diffusion curve, but also the economic imperative associated with it, as shown in the graphic below. The reality is that the market fabric is a fractal tissue, made of a multitude of diffusion curves. You have the actual technology evolution as shown in the graph below, for each of these curves you have the same similar sub-curve representing the various adoption rate. These sub-curves are then subdivided and overlapped with smaller ones created by each company's product/services competing within the space.
This overall complex fabric creates a difficult environment for determining the correct strategy to apply. Identifying the current state of the ecosystem, its direction and when to adapt is a daunting task with a multitude of variables to take into consideration (which I might try to take a stab at in a future post). For the lucky or for the visionary, that spot the trend early enough, they may then attempt to sell early, or pivot their strategy. Pivoting their strategy is a rather difficult operation to execute correctly or even at the right time. Too early or too late and you can lose momentum of the current diffusion wave while the next one might not have picked up yet. In this case, your capacity to wait it out depends ruthlessly on your burn rate. Many companies fail at that stage simply because of bad timing.
To conclude, often when a product, company or startup claims to have failed in their endeavours because they were “ahead of their time”, this is a misconception. In reality and unfortunately in the majority of cases, they simply did not understand the ecosystem they had evolved in and got stuck in a local maxima. For some, it turned into a kiss of death while others, into a curse of
zombification.