Google released a new OCI container runtime: gVisor. This runtime aim at solving part of the security concerns associated with the current container technology stack. One of the big argument of the virtualisation crowd has always been that the lack of explicit partitioning and protection of resource can facilitate “leakage” from the containers to the host or other adjacent containers.
This stem from the historical evolution of containers in Linux. Linux has no such concept of native containers. Not like BSD with Jails or Solaris with Zones. Containers in Linux are the result of the gradual emergence of a stack of various security and isolation technology that was introduced in the Linux kernel. As a result, Linux ended up with a highly broad technology stack that can be separately turned on / off or tuned. However, there is no such thing as a pure sandbox solution. The classic jack of all trade curse, it’s a master of none solution.
The Docker runtime (Containerd) package all the Linux kernel isolation and security stack (namespaces, cgroup, capabilities, seccomp, apparmor, SELinux) into a neat solution that is easy to deploy and use.
It allows the user to restrict what the application can do such as which file it can access with which permission or limits resource consumption such as networks, disk I/O or CPU. It allows the applications to share resources without stepping on each other toes happily. Also, limits the risk any of their data being accessed while sitting on the same machine.
With a correct configuration ( the default one is quite reasonable ) will allow blocking anything that is not authorised and in principle protect from any leak from a malicious or badly coded piece of code running in the container.
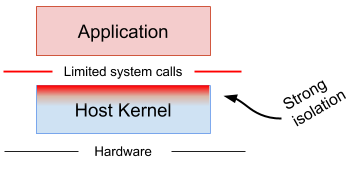
However, you have to understand that Docker has some real limitation already. It has only limited support for user-namespace. The user-namespace allows applications to have UID 0 permission within the containers ( aka root ) while the containers and user running has a lower privilege level. As a result, each container would run under a different user ID without stepping on each other toes.
All of these features rely on the reliability and security (as in no bugs) of the Linux kernel. Most of Docker advanced feature relies on kernel features. And getting new features is a multi-year effort, it took a while for good resource isolation mechanism percolates from the first RFC to the stable branch by example. As a result, Docker and current container ecosystem are directly dependent on the Linux kernel update inertia as well as its code quality. While being excellent, no system is entirely free of bug, not to mention the eternal race for patching them when they are discovered and fixed.
Hence the idea is to, rather than having to share the kernel between all the containers, have one kernel per container. Explicitly limiting potential leakage, interference and reduce the attack surface. gVisor adopts this approach, which is not new as KataContainers already implemented something similar. Katacontainers is the result of the fusion of ClearContainer (intel) and runV (hyper). Katacontainers use KVM as a minimalistic kernel dedicated to the container runtime. But, you still need to manage the host machine to ensure fair resource sharing and their securitisation. This additional layer of indirection limits the attack surface as even if a kernel bug is discovered you will be challenged to exploit it to escape to another an adjacent container or underlying one as they are not shared.
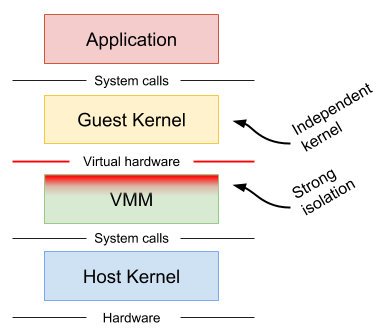
gVisor can use a KVM as kernel; however, it was initially and is still primarily designed around ptrace. User Mode Linux already used the same technique, which is to start a process in userspace for the subsystem that will be running on top. Similarly to a hypervisor model used by virtual machines. All the system calls will be executed using the permission of the userspace process on behalf of the subsystem via an interception mechanism.

Now, how do you intercept these system calls which should be executed by the kernel? UML and gVisor divert ptrace primary goal ( which is debugging ) and inject a breakpoint in the executable code to intercept and stop for every system call execution. Once caught the new userspace kernel will execute the call on behalf the original process within userspace. It works well, but as you guessed, there is no free lunch. This method what heavily used by the first virtualisation solution. But rapidly, processor vendors realised that offering hardware-specific acceleration method would be highly beneficial ( and sell more at the same time).
KVM and other hypervisor leverage such accelerator. Now you even have AWS and Azure deploying completely dedicated coprocessor for handling virtualization related acceleration. Allowing VM to run almost that the same speed as a bare metal system.
And like Qemu leveraging KVM, gVisor also offer KVM as underlying runtime environment. However, there is significant work to be done to enable any container to run on to of it. While ptrace allow to directly leverage existing Linux stack, with KVM you need need to reimplement a good chunk of the system to make it work. Have a look at Qemu code to understand the complexity of the task. This is the reason behind the limited set of supported applications as not all syscalls are implemented yet.
As is, gVisor is probably not ready yet for production. However, this looks like a promising solution providing a middle ground between the Docker approach and the Virtualization one while taking some of the excellent ideas coming from the unikernel world. I hope that this technology gets picked up, and the KVM runtime becomes the default solution for gVisor. It will allow the system to benefit from a rock-solid hardware acceleration with all the paravirtualisation goodies such as virtio.
No comments :
Post a Comment